


How to Secure Sensitive Data Across Hybrid Environments
Bill Schaumann
Today, many organizations maintain and process personally Identifiable information (PII) across a variety of data environments. From traditional data centers, cloud storage, or third-party SaaS providers, data is stored in shared network drives, databases, and large data lakes. The processing of PII has grown beyond the confines and controls of on-prem data center environments where access to data is protected by local firewalls, router ACL lists, and DMZ partitions.
The Challenge of Managing Data in Hybrid Environments
Finding and organizing the sensitive data related to an individual across multiple data environments can be a challenging requirement to fulfill. Data is often duplicated for new uses, stored in new repositories, or forgotten about altogether, taking up storage space on remote servers and shared network drives. Meeting this challenge and maintaining an inventory of sensitive data types and processing activities across these environments can assist companies in meeting their regulatory obligations and reducing the risk of breach.
Building an Identity-Centric Data Inventory
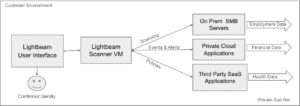
Lightbeam connects to applications and data sets regardless of where the data is stored. From AWS and Azure clouds to third-party applications, private clouds or on-prem data centers. Lightbeam can find and assimilate the data of employees, customers, or consumers whose data is collected, stored, and processed.
Hybrid environments
Bits and pieces of a person’s identity can be scattered across many repositories. Financial data, Healthcare data, or Employment data are stored in separate data stores and processed by separate applications. Lightbeam’s ability to form an identity from the bits and pieces of data strung across a hybrid environment is the basis for a sensitive data inventory
Keep an eye on the prize
Collecting data about an individual in an environment is difficult to begin with, but becomes exponentially more difficult when data is spread across multiple environments. Scanning data to form a picture of an identity across repositories requires the ability to contextually cross-reference disparate parts of an identity to pull them together to form a clear picture of the identity. The Lightbeam platform has the flexibility to attach to a wide variety of data repositories, find and classify sensitive data, and enforce data protection controls to protect what is important to the organization.
FAQ Section
Q1: What is a hybrid data environment?
A hybrid data environment includes a mix of on-prem systems, cloud platforms, and SaaS applications where data is stored and processed.
Q2: Why is sensitive data discovery important in hybrid environments?
Because data is fragmented across systems, organizations need automated discovery to locate PII, ensure compliance, and reduce breach risk.
Q3: What challenges exist in managing hybrid cloud data?
Key challenges include data duplication, lack of visibility, inconsistent access controls, and difficulty maintaining a unified data inventory.
Q4: How does data governance work across hybrid environments?
It combines discovery, classification, access control, and policy enforcement across all data sources—cloud, SaaS, and on-prem.
Q5: How does LightBeam help secure hybrid environments?
LightBeam connects across environments, maps data to identities, and enforces governance policies to ensure continuous visibility and control.
